WSSS(Weakly Supervised Semantic Segmentation) 소개
Date:
WSSS
- Weakly Supervised Semantic Segmentation
- segmentation를 수행할때 Pixel label이 없을경우, image label나 box label등의 약한 Label로 segmentation을 수행하는 Task
- 필요성 : pixel level의 annotation을 진행할때 걸리는 시간이 일반 image level의 classification의 78배가 걸림

- Weak Supervision : Test시에 요구하는 Output(pixel-level labels)보다 간단한 annotation(image, point level labels)을 이용하여 학습

Naive approach
-
주어진 Image data를 활용하여 해당 Data의 label level 단위에서 학습진행(Classification, detection ..)
-
학습한 모델에서 CAM, Grad-CAM, Attention을 추출
-
추출한 결과물에서 image의 pseudo mask를 뽑아내어 모델 학습에 이용
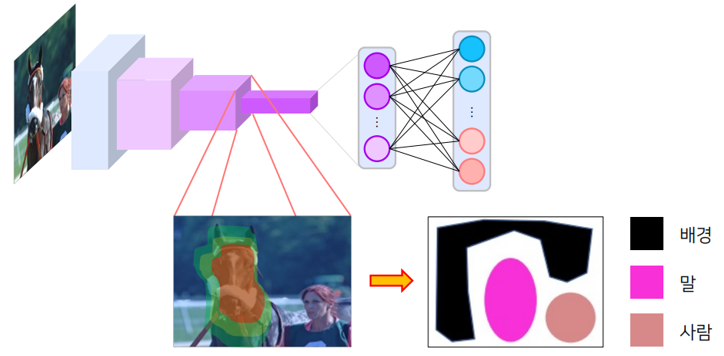
🚨 pseudo mask의 결과가 좋지 않음
CAM 기반의 접근
CAM & Grad-CAM
- CAM : Class Activation Mapping
- Classification 모델을 학습하면서 모델이 Class의 물체가 어떤 영역을 바라보고 있는지 확인할 수 있음

- CAM 원리
- object의 특징을 표현하는 Feature map이 존재함
- Scoring시 이런 Feature map 중 object를 구분하는데 필요한 특징들을 모아 weight를 다르게 부여하여 Object 분류

- CAM의 문제점
- 마지막 Layer는 GAP(혹은 Flatten)작업이 필요하여, 일반적인 적용이 불가능
- 마지막 Layer에서만 CAM을 뽑아낼 수 있고, 이전 Layer에서는 어떻게 활성화가 되는지 확인할 수 없음
- Grad CAM
- CAM의 문제점을 극복하기 위한 시도
- CAM에서 feature map의 GAP의 weight가 아닌, faeture의 변화에 따른 Class Score의 변화
- 특정 feature map에 변화가 있을때 Class에 score가 크게 변화하면 중요도가 높은 feature map, class score가 작게 변화하면 중요도가 낮은 feature map
- score 변화량 / feature map 변화량 = 기울기 = 미분값으로 중요도 정해짐
- GAP가 아닌 feature map 모든 위치의 미분값 평균으로 weight를 구함


- CAM & Grad CAM의 문제점
- 결과가 Sharp 하지 않고, 뭉게지거나, 둥글둥글한 모양임
- 입력 Image의 크기와 Feature map의 크기의 차이로 인한 문제
- 크기를 맞춰주기 위해 upsampling을 진행하며 관련 문제가 발생함
CAM을 Sharp하게 만들기 위한 접근
- 입력 이미지와 Feature map의 크기 차이로 인해서 upsampling 과정으로 동글동글한 형태로 출력되게됨

1. 물체 형태 제공
- 예측한 Segmentation 영역에 CRF를 적용한 값과 segmentation의 차이 값을 boundary loss로 활용하여 학습(model output과 CRF output 값이 같아지도록 KL Divergence loss를 사용)

2. Transfer Learning
- MSRA10K saliency object dataset로 학습한 Network를 이용
- 뽑아낸 CAM의 결과와 Saliency 예측한 결과를 적절하게 합쳐서 sharp한 결과를 얻는 방법
- Saliency 뜻은 특징, 돌출의 뜻을 가지고 있는데, Computer Vision에서는 image를 봤을때 처음 보이는 object를 의미함, 그 이미지의 중심이 되는 object와 배경 두 가지로 구분하는 방식을 Saliency라고 함

3. Self -Supervised Learning
- 입력된 이미지의 크기에 따라 CAM이 다른 부분을 관측함
- 입력된 이미지의 크기와 상관없이 같은 CAM 모양을 갖도록 학습

CAM 영역 확장
- CAM은 특징적인 영역에만 집중하는 경향이 있어 영역이 좁아지는 문제가 있음
- Classification등 다른 Task를 통해 Segmentation을 간접적으로 학습하다보면, 물체를 정확하게 구분해야할 이유가 적음
- 확실하게 Class를 알 수 있는 특징에 의존하게됨
1. 특징적인 영역 Erase
- object의 여러곳을 볼수 있도록 특징적인 영역을 지워가며 지속 학습
- 입력 이미지 CAM 추출
- CAM의 결과 영역 제거
- 독립인 새로운 네트워크로 재학습하여 CAM 추출
- 위 과정 반복하여 학습 진행

- 단점
- 여러 Network가 필요함
- Over-Erasing : 과도하게 진행되면 물체가 아닌 영역까지 Mask가 생기는 현상이 있음

2. Patch Cutout
- 이미지의 Random 영역을 patch를 지워 최대한 다양한 영역에서 특징을 뽑을 수 밖에 없도록함

3. 1번을 하나의 Network로 수행

4. 다양한 Receptive Field 사용

5. Mixup

📌reference
- boostcourse AI tech
💡 수정 필요한 내용은 댓글이나 메일로 알려주시면 감사하겠습니다!💡
댓글